Ethics and data
Responsible by design, not as an afterthought
Applying AI to cultural heritage raises questions that go beyond the usual checklist: biased training data, copyright on collections, and the risk of distorting the stories heritage tells. The project treats these as research questions in their own right.
The framework
An AI ethics assessment framework, applied throughout
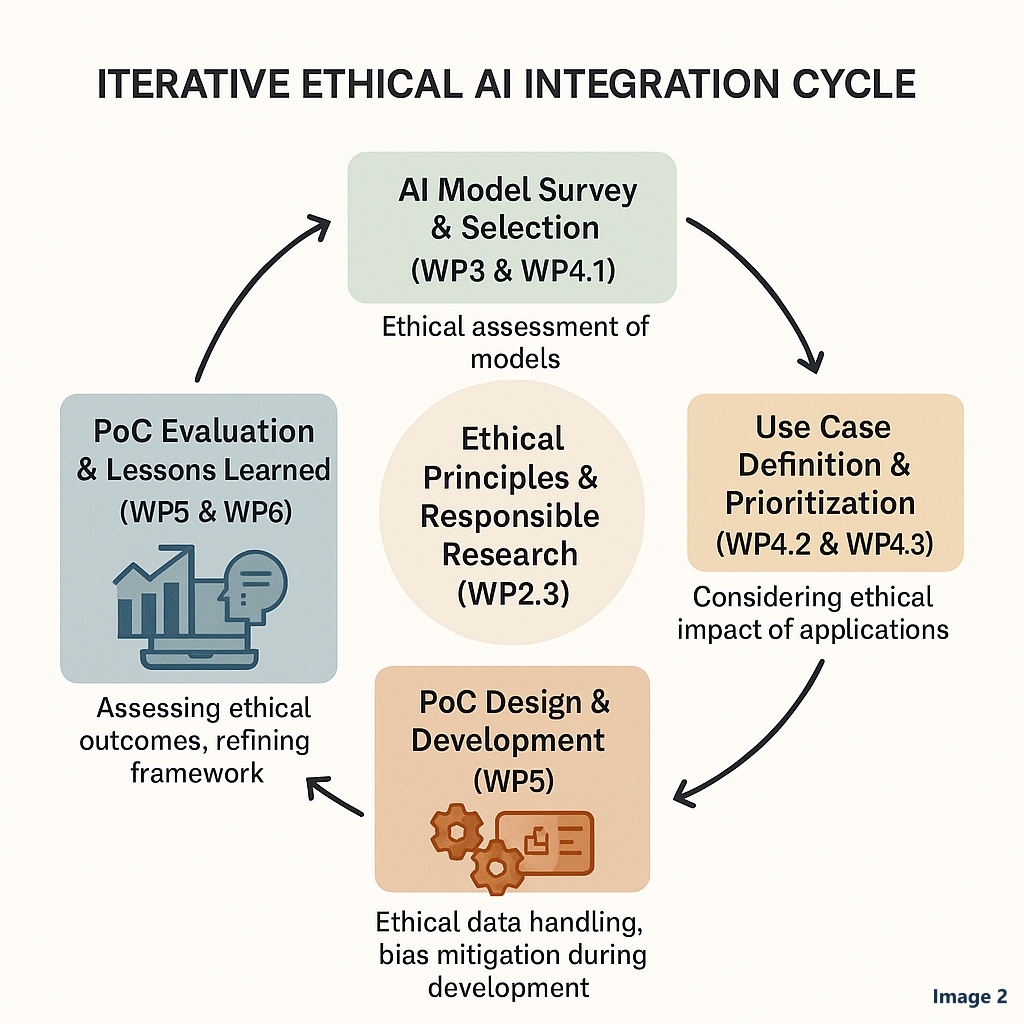
Early in the project we develop a dedicated AI ethics assessment framework, due in month 12. It draws on cross-sectoral principles such as the GDPR and the UNESCO recommendation on AI ethics, and on AI-specific frameworks like the EU AI Act and the guidelines of the European high-level expert group on AI.
The framework is not a document that gets written once and shelved. It guides how models are selected, how data is prepared, and how the proofs of concept are evaluated. In concrete terms, the project commits to:
- monitoring compliance with legal and institutional ethics standards;
- documenting how AI models are evaluated and selected, for transparency and accountability;
- actively identifying and addressing biases in data and algorithms, including socio-cultural, geographic and historical biases;
- addressing heritage-specific risks such as narrative distortion, decontextualisation and the misrepresentation of marginalised communities, through interdisciplinary dialogue and scenario-based testing with heritage professionals.
Throughout the project, an AI ethics issue log records the dilemmas we run into, the decisions taken and the mitigations applied. It is a transparent audit trail of how ethical reflection actually shaped the work, and it feeds into a final ethics report at the end of the project.
Research data
FAIR data, kept safe and kept local
A living data management plan
A data management plan aligned with the FAIR principles is delivered in month 6 and updated throughout the project. It covers collection, annotation, storage, versioning, access, sharing and long-term preservation.
The 3-2-1 backup rule
All project data is protected by a backup and security strategy following the 3-2-1 rule, combining institutional and external storage with controlled access and periodic restore testing.
Local AI by necessity
Some datasets are confidential and cannot be sent to external services without absolute guarantees. So the models come to the data: processing happens on the institute's own servers and GPUs.
Inclusivity
Whose heritage, whose data, whose AI?
Heritage collections reflect the times that produced them, including their imbalances. When an AI model trained on such data enriches a catalogue or translates a record, it can quietly amplify those imbalances. The project examines this directly: training data of candidate models is scrutinised for underrepresentation and stereotypes, outputs of the proofs of concept are checked for biased results, and metadata enrichment avoids gendered or cultural assumptions that the source material does not support.
The same lens applies to the project itself. Use cases are gathered from a diverse range of stakeholders, dissemination targets all audiences in inclusive language, and internal workshops build AI literacy across the institute, so the benefits of these tools are not reserved for the technically inclined.