Application 01
Reverse image search
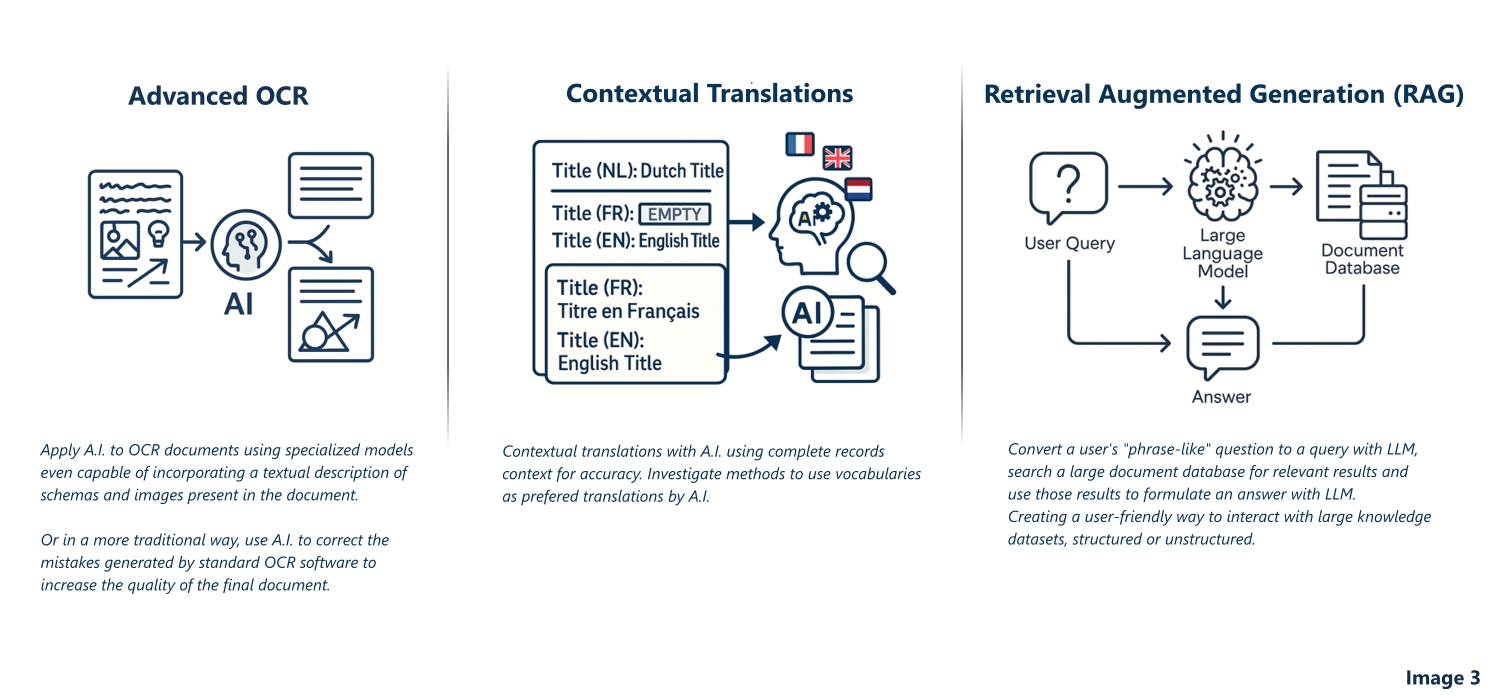
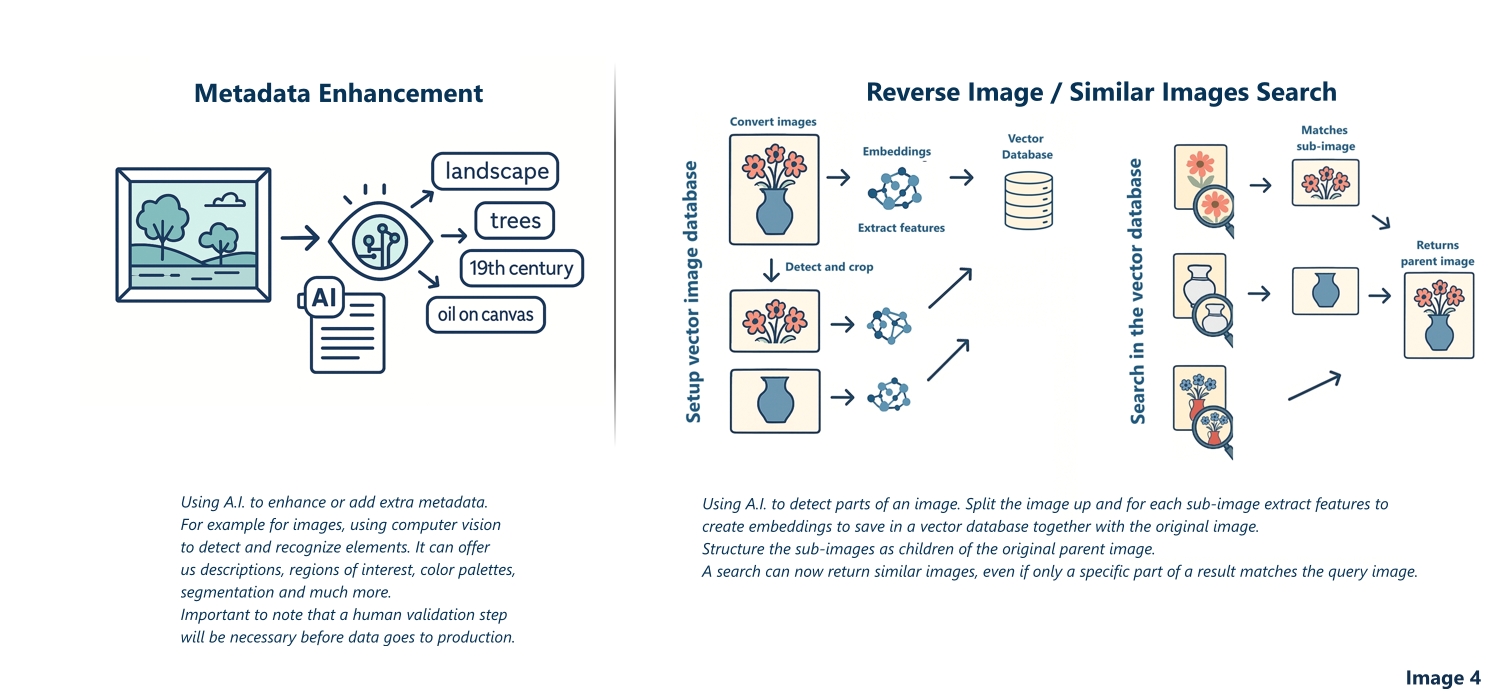
KIK-IRPA's photo library holds well over a million images of Belgian heritage. Finding "that other photograph of the same altarpiece" currently depends on whoever catalogued it choosing the right keywords decades ago.
What we are testing. Models that convert images into embeddings, stored in a vector database, so that a search can run on visual similarity instead of keywords. By detecting and indexing parts of images separately, a search can even match a detail, such as a single figure in a larger scene, and lead you back to the parent image.
Why it matters. Art historians and conservators could trace related photographs, copies, studio variants and details across the collection in seconds, including connections nobody thought to catalogue.